I La
place du processeur dans l'ordinateur
1/ Le fonctionnement des processeurs.
Le processeur noté CPU (central
processing unit) est le cerveau de l'ordinateur. Au début ils étaient conçus
spécifiquement pour un ordinateur d’un type donné, mais par la suite cela
changea.
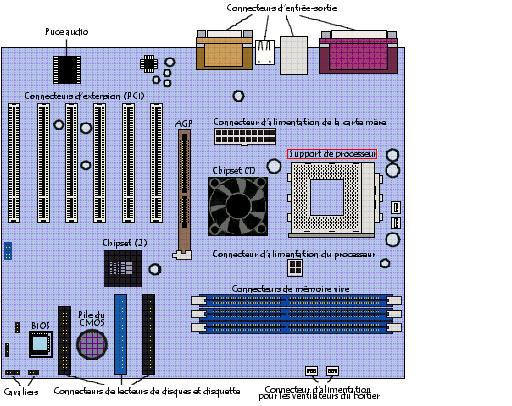
Il est situé sur la carte mère (circuit imprimé qui porte les principaux composants électroniques soit : le processeur, la mémoire, le chipset et l'horloge, ...)
Le
processeur permet de manipuler des informations numériques et d'exécuter les
instructions stockées en mémoire.
Aujourd’hui, les processeurs sont basés sur des architectures et des techniques
de parallélisassions des traitements différents qui ne permettent plus de
déterminer leur puissance.
De plus,
c’est le processeur qui apporte aux ordinateurs leur capacité à être programmé.
Ce composant est nécessaire à tous les ordinateurs.
a)
Les composants du processeur et leur
rôle.
Les éléments essentiels d'un processeur sont :
·
l'horloge,
qui synchronise toutes les actions de l'unité centrale. Elle a une fréquence (ou
cycle) qui correspond au nombre d'impulsions par seconde exprimé en hertz (Hz).
Elle exécute une action à chaque "top", cette action correspond à une
instruction. L'indicateur CPI (cycle par instructions) permet de représenter le
nombre d'instructions nécessaire à l'exécution d'une instruction.
·
l'Unité
Arithmétique (UAL),
qui prend en charge les calculs élémentaires tels que les additions,
soustractions, multiplications ou division. Et les opérations logiques ; ET, OU,
Ou exclusif, ...
·
les
registres,
ce sont des mémoires de petites tailles et rapides pour que l'UAL puisse
manipuler leur contenu à chaque cycle d'horloge. Leur nombre varie selon les
processeurs et il existe différents registres :
- registre accumulateur : il stocke les données en cours de
traitement par l'UAL (soit opérations arithmétiques et
logiques
- registre d'état : permet de stocker les informations
concernant le résultat de la dernière instruction exécutée.
- registre d'instruction : (RI) contient l'instruction en cours
de traitement.
- registre tampon : il stocke temporairement une donnée
provenant de la mémoire
- registre généraux : ces registres sont disponibles pour les
calculs
- registre d'adresses : il contient l'adresse de la prochaine
information à lire par l'UAL, soit la prochaine instruction.
- compteur ordinal : (CO) contient l'adresse de la prochaine
instruction à traiter.
- le pointeur de pile : ce registre dont le nombre varie en
fonction du type de processeur contient l'adresse du
sommet de la pile.
·
L’unité
d’entré-sortie,
il prend en charge la communication avec la mémoire de l’ordinateur ou la
transmission des ordres destinés à piloter ses processeurs spécialisés qui
permettent à l’ordinateur d’accéder aux périphériques de l’ordinateur.
De nos
jours, les processeurs intègrent des éléments plus complexes comme :
·
L’architecture surperscalaire,
elle consiste à disposer plusieurs unités de traitements en parallèle afin de
pouvoir traiter plusieurs instructions par cycle.
·
L’architecture superpiline,
elle permet de découper temporellement les traitements à effectuer.
·
L’unité
de calcul de virgule flottante,
elle permet d’accélérer les calculs sur des nombres réels codés en virgule
flottante
·
La
mémoire cache,
elle permet d’accélérer les traitements tout en diminuant le temps d’accès à la
mémoire. Ces mémoires tampons sont en effet bien plus rapides que la RAM et
ralentissent moins le CPU. Le cache d’instruction reçoit les prochaines
instructions à exécuter, le cache donné manipule les données. Parfois un seul
cache unifié est utilisé pour le code et les données. Plusieurs niveaux de
caches peuvent coexister, on les désigne souvent sous les noms de
L1, L2 ou L3 :
-La mémoire cache de premier niveau (appelée L1 Cache, pour Level
1 Cache) est directement
intégrée dans le processeur. Elle se subdivise en 2 parties :
>La première est le cache
d'instructions, qui contient les instructions issues de la mémoire vive décodées
lors de passage dans les pipelines.
>La seconde est le cache de
données, qui contient des données issues de la mémoire vive et les données
récemment utilisées lors des opérations du processeur.
Les caches du premier niveau sont très rapides d'accès. Leur délai d'accès tend
à s'approcher de celui des registres internes aux processeurs.
-La mémoire cache de second niveau (appelée L2 Cache, pour Level
2 Cache) est située au niveau du boîtier contenant le processeur (dans la
puce). Le cache de second niveau vient s'intercaler entre le processeur avec son
cache interne et la mémoire vive. Il est plus rapide d'accès que cette dernière
mais moins rapide que le cache de premier niveau.
-La mémoire cache de troisième niveau (appelée L3 Cache, pour Level 3 Cache) est située au niveau de la carte mère.
Les processeurs sont donc définis par :
• la largeur de ses registres internes de manipulation de données (8, 16, 32,
64, 128) bits ;
• la cadence de son horloge exprimée en MHz (mega hertz) ou GHz (giga hertz) ;
• le nombre de noyaux de calcul (core) ;
• son jeu d'instructions (ISA en anglais, Instructions Set Architecture)
dépendant de la famille (CISC, RISC, etc.) ;
• Sa finesse de gravure exprimée en nm (nanomètres) et sa microarchitecture.
Mais ce qui caractérise principalement le processeur est la famille à laquelle
il appartient.
En effet il existe plusieurs familles :
·
CISC
(Complex Instruction Set Computer : choix d'instructions aussi proches que
possible d'un langage de haut niveau)
est une technologie basée sur un jeu de plus de
200 instructions. La complexité de ces instructions fait que l’une d’entre elles
peut prendre plusieurs cycles pour être exécutée.
·
RISC
( Reduced Instruction Set Computer : choix d'instructions plus simples et d'une
structure permettant une exécution très rapide) n’offre
que 128 instructions, dites de base. Mais
Une instruction peut être exécutée en un seul cycle. L’avenir des processeurs PC
passera
Forcément au RISC (cela implique la création de compilateurs complexes).
Un processeur RISC peut atteindre une vitesse d’exécution jusqu’à 70% plus
rapide qu’un CISC de même fréquence.
·
VLIW
(Very Long Instruction Word) ce concept fait repose rune partie de la gestion du
pipeline sur le compilateur : le processeur reçoit des instructions longues qui
regroupent plusieurs instructions simples
· DSP (Digital Signal Processor). Même si cette dernière famille (DSP) est relativement spécifique. En effet un processeur est un composant programmable et est donc a priori capable de réaliser tout type de programme. Toutefois, dans un souci d'optimisation, des processeurs spécialisés sont conçus et adaptés à certains types de calculs (3D, son, etc.). Les DSP sont des processeurs spécialisés pour les calculs liés au traitement de signaux.
Un processeur possède trois types de
bus :
• un bus de données, définit la taille des données manipulables (indépendamment
de la taille des registres internes) ;
• un bus d'adresse définit le nombre de cases mémoire accessibles ;
• un bus de contrôle définit la gestion du processeur IRQ, RESET etc.
b) le fonctionnement du processeur.
1 les transistors
Pour effectuer le traitement de l'information, le microprocesseur possède un
ensemble d'instructions, appelé « jeu
d'instructions », réalisées grâce à des circuits électroniques. Plus
exactement, le jeu d'instructions est réalisé à l'aide de semi-conducteurs, «
petits interrupteurs » utilisant l'effet
transistor, découvert en 1947 par John Barden, Walter H.
Brattain et William Shockley qui reçurent le prix Nobel en 1956 pour
cette découverte.
Un transistor (contraction de
résistance de transfert) est un composant électronique semi-conducteur,
possédant trois électrodes, capable de modifier le courant qui le traverse à
l'aide d'une de ses électrodes (appelée électrode de commande). On parle ainsi
de «composant actif», par opposition aux « composants passifs », tels que la
résistance ou le condensateur, ne possédant que deux électrodes (on parle de «
bipolaire »).
Le transistor MOS (métal, oxyde, silicium) est le type de transistor
utilisé pour la conception de circuits intégrés.
Il est composé de deux zones chargées négativement, appelées
respectivement source (possédant
un potentiel quasi-nul) et drain (possédant
un potentiel de 5V), séparées par une région chargée positivement, appelée. Le
substrat est surmonté d'une électrode de commande, appelée porte permettant
d'appliquer une tension sur le substrat.

Lorsqu'aucune tension n'est appliquée à l'électrode de commande, le substrat
chargé positivement agit comme une barrière et empêche les électrons d'aller de
la source vers le drain. En revanche, lorsqu'une tension est appliquée à la
porte, les charges positives du substrat sont repoussées et il s'établit un
canal de communication, chargé négativement, reliant la source au drain.

Le transistor agit donc globalement comme un interrupteur programmable grâce à
l'électrode de commande. Lorsqu'une tension est appliquée à l'électrode de
commande, il agit comme un interrupteur fermé, dans le cas contraire comme un
interrupteur ouvert.
Le rôle des unités centrales de traitement est d'exécuter
une série d'instructions stockées appelées "programme".
Les instructions et les données transmises au processeur sont exprimées en mots
binaires. Elles sont stockées dans la mémoire. Le séquenceur ordonne la lecture
du contenu de la mémoire et la constitution des mots présentés à l'ALU qui les
interprète.
L’ensemble des instructions et des données constitue un programme.
Le langage le plus proche du code machine tout en restant lisible par des
humains est le langage d’assemblage, aussi appelé langage assembleur. Toutefois,
l’informatique a développé toute une série de langages, dits de haut niveau
(comme le BASIC, Pascal, C, C++, etc.), destinés à simplifier l’écriture des
programmes.
Les opérations décrites ci dessous sont conformes à l'architecture de Von
Neumann. Le programme est représenté par une série d'instructions qui réalisent
des opérations en liaison avec la mémoire vive de l'ordinateur. Il y a quatre
étapes que presque toutes les architectures Von Neumann utilisent :
• FETCH (Recherche de l'instruction) ;
• DECODE (Décodage de l'instruction : opérations et opérandes) ;
• EXECUTE (Exécution des opérations) ;
• WRITEBACK (Ecriture du résultat).
Le diagramme mon

La première étape, FETCH (recherche), consiste à
rechercher une instruction dans la mémoire vive de l'ordinateur. L'emplacement
dans la mémoire est déterminé par le compteur de programme (PC), qui stocke
l'adresse de la prochaine instruction dans la mémoire de programme. Après qu'une
instruction a été recherchée, le PC est incrémenté par la longueur du mot
d'instruction. Dans le cas de mot de longueur constante simple, c'est toujours
le même nombre. Par exemple, un mot de 32 bits de longueur constante qui emploie
des mots de 8 bits de mémoire incrémenterait toujours le PC par 4 (excepté dans
le cas des sauts). Le jeu d'instructions qui emploie des instructions de
longueurs variables comme l'x86, incrémentent le PC par le nombre de mots de
mémoire correspondant à la dernière longueur d'instruction. En outre, dans des
unités centrales de traitement plus complexes, l'incrémentation du PC ne se
produit pas nécessairement à la fin de l'exécution d'instruction. C'est
particulièrement le cas dans des architectures fortement parallélisées et
superscalaires. Souvent, la recherche de l'instruction doit être opérée dans des
mémoires lentes, ralentissant l'unité centrale de traitement qui attend
l'instruction. Cette question est en grande partie résolue dans les processeurs
modernes par l'utilisation de caches et d'architectures pipelines.
L'instruction que le processeur recherche en mémoire est utilisée pour
déterminer ce que le CPU doit faire. Dans l'étape DECODE (décodage),
l'instruction est découpée en plusieurs parties telles qu'elles puissent être
utilisées par d'autres parties du processeur. La façon dont la valeur de
l'instruction est interprétée est définie par le jeu d'instructions (ISA) du
processeur 2. Souvent, une partie d'une instruction, appelée opcode (code
d'opération), indique quelle opération est à faire, par exemple une addition.
Les parties restantes de l'instruction comportent habituellement les autres
informations nécessaires à l'exécution de l'instruction comme par exemples les
opérandes de l'addition. Ces opérandes peuvent prendre une valeur constante,
appelée valeur immédiate, ou bien contenir l'emplacement où retrouver (dans un
registre ou une adresse mémoire) la valeur de l'opérande, suivant le mode
d'adressage utilisé. Dans les conceptions anciennes, les parties du processeur
responsables du décodage étaient fixes et non modifiables car elles étaient
codées dans les circuits. Dans les processeurs plus récents, un microprogramme
est souvent utilisé pour traduire les instructions en différents ordres. Ce
microprogramme est parfois modifiable pour changer la façon dont le CPU décode
les instructions, même après sa fabrication.
Diagramme fonctionnel d'un processeur simple

Après
les étapes de recherche et de décodage arrive l'étape EXECUTE (exécution) de
l'instruction. Au cours de cette étape, différentes parties du processeur sont
mises en relation pour réaliser l'opération souhaitée. Par exemple, pour une
addition, l'unité arithmétique et logique (ALU) sera connectée à des entrées et
des sorties. Les entrées présentent les nombres à additionner et les sorties
contiennent la somme finale. L'ALU contient la circuiterie pour réaliser des
opérations d'arithmétique et de logique simples sur les entrées (addition,
opération sur les bits). Si le résultat d'une addition est trop grand pour être
codé par le processeur, un signal de débordement est positionné dans un registre
d'état.
La dernière étape WRITEBACK (écriture du résultat), écrit tout simplement les
résultats de l'étape d'exécution en mémoire. Très souvent, les résultats sont
écrits dans un registre interne au processeur pour bénéficier de temps d'accès
très courts pour les instructions suivantes. Dans d'autres cas, les résultats
sont écrits plus lentement dans des mémoires RAM, donc à moindre coût et
acceptant des codages de nombres plus grands.
Certains types d'instructions manipulent le compteur de programme plutôt que de
produire directement des données de résultat.
Ces instructions sont appelées des sauts (jumps) et permettent de réaliser des
boucles (loops), des programmes à exécution conditionnelle ou des fonctions
(sous-programmes) dans des programmes 3. Beaucoup d'instructions servent aussi à
changer l'état de drapeaux (qui est une valeur binaire indiquant le résultat
d’une opération ou le statut d’un objet) (flags) dans un registre d'état. Ces
états peuvent être utilisés pour conditionner le comportement d'un programme,
puisqu'ils indiquent souvent la fin d'exécution de différentes opérations. Par
exemple, une instruction de comparaison entre deux nombres va positionner un
drapeau dans un registre d'état suivant le résultat de la comparaison. Ce
drapeau peut alors être réutilisé par une instruction de saut pour poursuivre le
déroulement du programme.
Après l'exécution de l'instruction et l'écriture des résultats, tout le
processus se répète, le prochain cycle d'instruction recherche la séquence
d'instruction suivante puisque le compteur de programme avait été incrémenté. Si
l'instruction précédente était un saut, c'est l'adresse de destination du saut
qui est enregistrée dans le compteur de programme. Dans des processeurs plus
complexes, plusieurs instructions peuvent être recherchées, décodées et
exécutées simultanément, on parle alors d'architecture pipeline.
2/
Conception et implémentation.
a)
Sa
conception.
Les
processeurs sont tous gravés sur des plaques appelées Wafers. Les différentes
séries de processeurs n’ont pas forcément la même finesse de gravure, les
processeurs actuels sont gravés en 0,09µ et 0,065µ (soit 90 et 65 nanomètres).
Le fait de diminuer la finesse de gravure permet d’abaisser leur coût de
fabrication. Cette technique permet donc de produire plus de processeur à la
fois sur un Wafer et de diminuer la consommation du processeur et donc de la
quantité de chaleur produite ce qui permet d’abaisser la consommation d’énergie
et d’augmenter en fréquence. Une finesse de gravure accrue permet également de
loger plus de transistors dans le core du processeur et donc d’ajouter des
fonctionnalités supplémentaires tout en gardant une surface aussi compacte que
les générations précédentes.

b)
Le signal d’horloge.
Les processeurs ont un fonctionnement synchrone par nature. Cela veut dire
qu'ils fonctionnent au rythme d'un signal de synchronisation qui est le signal
d'horloge. Il prend souvent la forme d'une onde carrée périodique.
En calculant le temps maximum que prend
le signal électrique pour se propager dans les différentes branches des circuits
du processeur, le concepteur peut sélectionner la période appropriée
du signal d'horloge.
Cette période doit être supérieure au temps que prend le signal pour se propager
dans le pire des cas. En fixant la période de l'horloge à une valeur bien
au-dessus du pire des cas de temps de propagation,
il est possible de concevoir entièrement le processeur et la façon dont il
déplace les données autour des "fronts" montants ou descendants du signal
d'horloge. Ceci a pour avantage de simplifier significativement le processeur
tant du point de vue de sa conception que de celui du nombre de ses composants.
Par contre, ceci a pour inconvénient de ralentir processeur. En effet sa vitesse
doit s'adapter à celle de son élément le plus lent, même si d'autres parties
sont beaucoup plus rapides. Ces limitations sont largement compensées par
différentes méthodes d'accroissement du parallélisme des processeurs.
Les améliorations d'architecture ne peuvent pas, à elles seules, résoudre tous
les inconvénients des processeurs globalement synchrones. Par exemple, un signal
d'horloge est sujet à des retards comme tous les autres signaux électriques.
Les fréquences d'horloge
plus élevées que l'on trouve dans les processeurs à la complexité croissante
engendrent des difficultés pour conserver le signal d'horloge en phase synchronisé
à travers toute l'unité centrale de traitement. En conséquence, beaucoup des
processeurs d'aujourd'hui nécessitent la fourniture de plusieurs signaux
d'horloge identiques de façon à éviter que le retard d'un seul signal ne puisse
être la cause d'un dysfonctionnement du processeur. La forte quantité de chaleur
qui doit être dissipée par le processeur constitue un autre problème majeur dû à l'accroissement des fréquences d'horloge. Les
changements d'état fréquents de l'horloge font commuter un grand nombre de
composants, qu'ils soient ou non utilisés à cet instant. En général, les
composants qui commutent utilisent plus d'énergie que
ceux qui restent dans un état statique. Ainsi, plus les fréquences d’horloge
augmentent et plus la dissipation de chaleur en fait autant, ce qui fait que les
processeurs requièrent des solutions de refroidissement plus efficaces.
c)
Le parallélisme.
Le parallélisme consiste
à exécuter simultanément, sur des processeurs différents, des instructions
relatives à un même programme. Cela se traduit par le découpage d'un programme
en plusieurs processus traités en parallèle afin de gagner en temps d'exécution.
Ce type de technologie nécessite toutefois une synchronisation et une
communication entre les différents processus.
Le fonctionnement de celle ci peut être très perturbé lorsque la communication
entre les processus ne fonctionne pas correctement.

d)
Le pipeline
Le pipeline
est une technologie visant à permettre une plus grande vitesse
d'exécution des instructions en parallélisant des étapes.
Pour comprendre le mécanisme du pipeline, il est nécessaire de comprendre les
phases d'exécution d'une instruction que nous avons expliquée auparavant.
Pour rappel, les phases d'exécution d'une instruction pour un processeur
contenant un pipeline à 5 étages sont les suivantes :
·
LI :
Lecture de l'Instruction (en
anglais FETCH
instruction) depuis
le cache ;
·
DI : Décodage
de l'Instruction (DECODE
instruction) et recherche des opérandes (Registre ou valeurs immédiate);
·
EX : Exécution
de l'Instruction (EXECUTE
instruction) (si ADD, on fait la somme, si SUB, on fait la soustraction,
etc.);
·
MEM : Accès
mémoire (MEMORY
access), écriture dans la mémoire si nécessaire ou chargement depuis la
mémoire ;
·
ER : Ecriture (WRITE(BACK)
instruction) de la valeur calculée dans les registres.
Les instructions sont organisées en file d'attente dans la mémoire, et sont
chargées les unes après les autres.
Grâce au pipeline, le traitement des instructions nécessite au maximum les cinq
étapes précédentes. Dans la mesure où l'ordre de ces étapes est invariable (LI,
DI, EX, MEM et ER), il est possible de créer dans le processeur un certain
nombre de circuits spécialisés pour chacune de ces phases.
L'objectif du pipeline est d'être capable de réaliser chaque étape en parallèle
avec les étapes amont et aval, c'est-à-dire de pouvoir lire une instruction (LI)
lorsque la précédente est en cours de décodage (DI), que celle d'avant est en
cours d'exécution (EX), que celle située encore précédemment accède à la mémoire
(MEM) et enfin que la première de la série est déjà en cours d'écriture dans les
registres (ER).

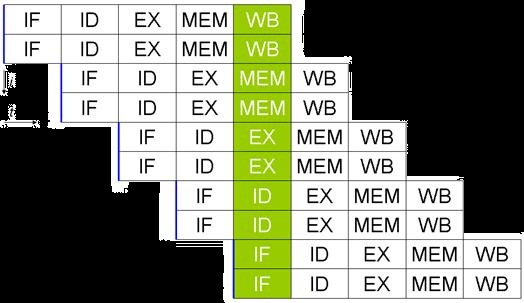
Il faut compter en général 1 à 2 cycles d'horloge pour chaque phase du pipeline,
soit 10 cycles d'horloge maximum par instruction. Pour deux instructions, 12
cycles d'horloge maximum seront nécessaires (10+2=12 au lieu de 10*2=20), car la
précédente instruction était déjà dans le pipeline. Les deux instructions sont
donc en traitement dans le processeur, avec un décalage d'un ou deux cycles
d'horloge). Pour 3 instructions, 14 cycles d'horloge seront ainsi nécessaires et
etc.
Il existe différents types de pipelines, de 2 à 40 étages, mais le principe
reste toujours le même.
La technologie superscalaire consiste
à disposer plusieurs unités de traitement en parallèle afin de pouvoir traiter
plusieurs instructions par cycle.
Conclusion :
Le processeur est donc le cerveau de
l’ordinateur bien qu’il ne cesse d’évoluer constamment. Cependant, une date clé
marque la création d’un nouveau type de processeur qui a permit d’améliorer
l’ordinateur, de le rendre plus fiable, d’augmenter sa vitesse d’exécution, de
le minimiser et donc le rendre moins cher. Cette nouvelle création est le
microprocesseur qui fut inventé en 1971 par
Marcian Hof.
C’est de cette évolution dont nous
parlerons dans notre deuxième partie.